データサイエンス
機械学習
AI
2025.02.03
忙しい人向けに、多すぎる生成AIのニュースの要点をざっくりまとめてみた

はじめに
最近は、生成AIの話題があちらこちらで盛り上がってますね。
あまりにニュースが多すぎて、正直なところ「ついていけてない……」と思っている人も多いのではないでしょうか?
よくわからないまま、ちまたで良いと叫ばれているツールにひたすら課金し、請求額がものすごいことになって冷や汗をかいた人もいるでしょう。(私です)
やはりこういうときには、情報に振り回されないためにも、核となる部分をざっくり把握しておくことが重要だと考えます。
そこで今回、「生成AIのコアの知識」および「最近のニュースの大まかな傾向」を整理してみました。
そもそも生成AIとは
生成AIとは、人間が作ったような自然なアウトプット(文章、プログラム、画像など)を生成できるAI(Artificial Intelligence:人工知能)のことです。 英語では「Generative AI」で、GenAI(ジェンエーアイ、ジェナイ)と書かれることもあります。 OpenAIが提供しているChatGPTは、この生成AIの機能をWeb上で使えるサービスで、大きな話題となりました。
さて、生成AIという言葉が出る前から、AIという言葉自体はありましたし、ときどき話題にもなっていましたよね。 そのAI(従来のAI)と生成AIは、何が違うのでしょうか?
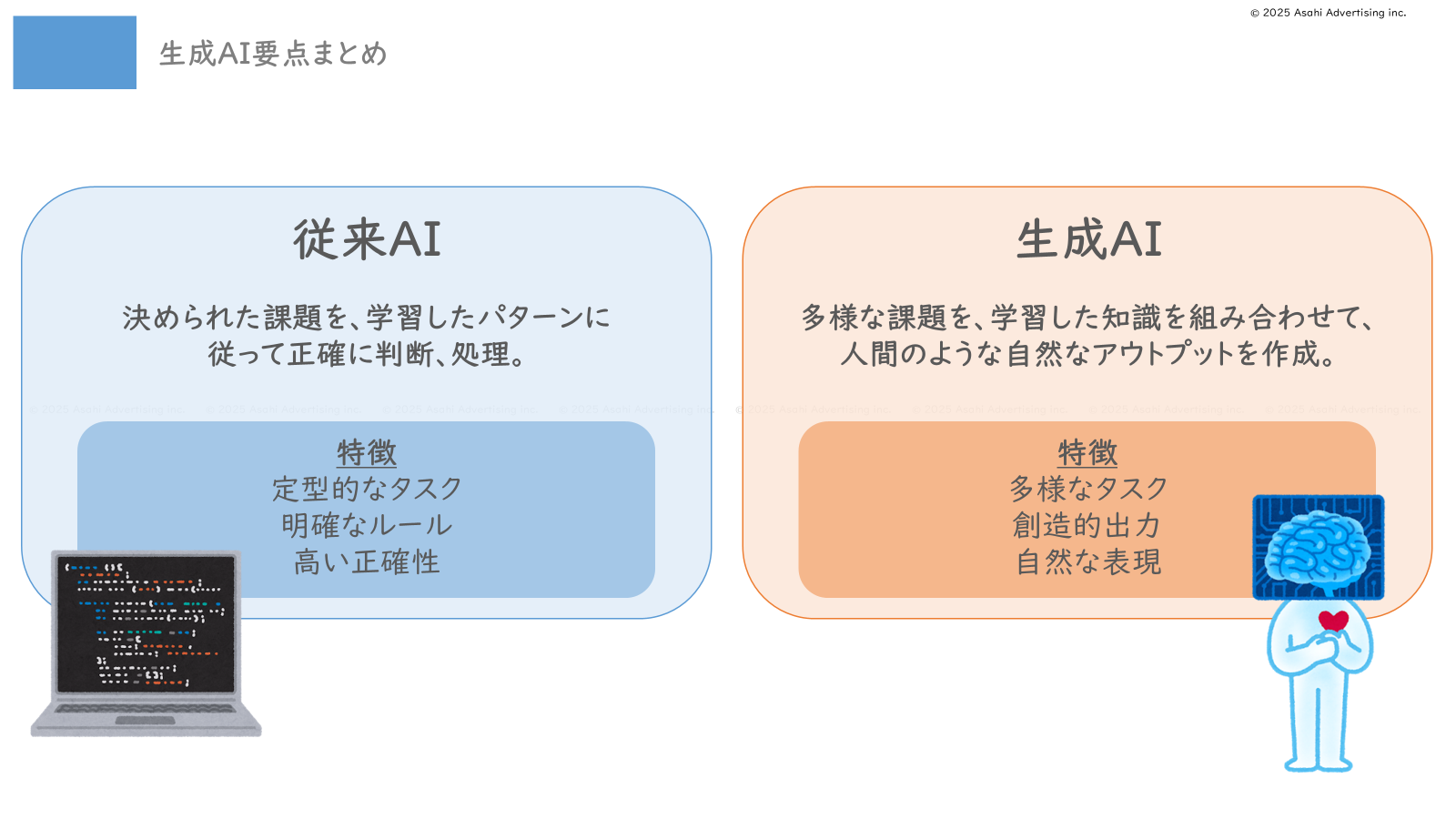
すごく大雑把に言えば、従来のAIは、機械学習という手法で主にデータの分類/判定や予測を行うものでした。 「カメラの映像から本人を特定する(顔認証)」や、「メールの内容からスパムメールを判定する(フィルタリング)」などがわかりやすい従来のAIを使った事例です。
簡単に言えば、従来のAIは「決められた課題を、学習したパターンに従って正確に判断・処理する」というものです。
一方、生成AIは「学習した知識を新しい方法で組み合わせ、人間のような自然な表現を作り出す」というAIです。従来のAIと比べると、さまざまな問題に対して柔軟に対応できるという点が大きな特徴です!
なお、生成AIにはテキスト生成や画像生成など、さまざまな種類があります。
その中でも、多くの人にとって最も身近な存在になるのは、ChatGPTに代表されるテキスト生成AIでしょう。
これらのテキスト生成AIは、LLM(Large Language Model:大規模言語モデル)と呼ばれる仕組みで動いているのです……!
大規模言語モデル(LLM)とは
ざっくり解説すると、LLMとは「まるで人間のように言葉を高度に理解する仕組み」です。
Transformerと呼ばれる、「文章の中の単語同士の関係性を効率的に分析できるすごい技術」を使って、膨大なテキストデータをコンピューターに読み込ませることで生まれたのです。
これにより、「この単語の次にはどんな単語が続きそうか」という確率を学習し、自然な文章を生成することができるようになったのです。
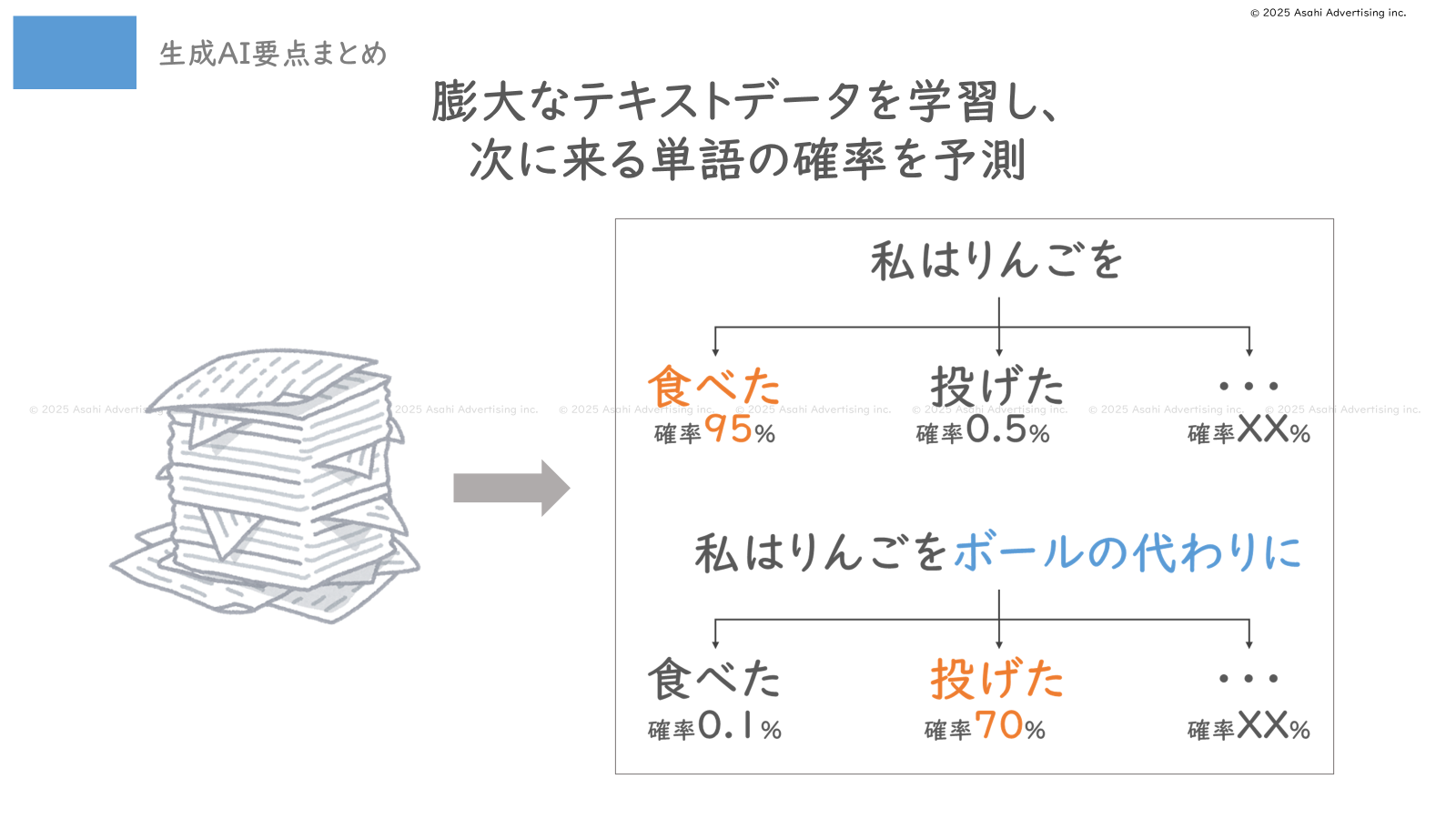
たとえば「私はりんごを」という文があったとします。
この文の続きは?と聞かれたら、ふつうは「食べた」というような言葉が来ると想像しますよね。「投げた」という言葉はあまり想定しないでしょう。
なぜならりんごは食べ物なので、投げるシチュエーションよりは食べるシチュエーションのほうが多く、自然と「りんご」と「食べた」という言葉はセットで使われるようになるからです。
これと同じように、コンピューターに人間が書いた膨大なテキストデータを与えることで、コンピューターは「りんご」と「食べた」という言葉がセットでよく出てくることを発見し、「『りんご』という単語が来たら、『食べた』という言葉が続く確率は95%、『投げた』は0.5%……」といった具合に学習していきます。
他にも「『ボールの代わりに』という言葉が来ると、『投げた』が70%、『叩いた』が15%……」というように、さまざまなパターンでの「次に出てくる単語の確率」を学習します。
その結果、「私はりんごを」という言葉を与えれば「食べた」という続きの語を出力し、「私はりんごをボールの代わりに」という言葉を与えれば「投げた」という続きの語を出力することができるようになり、かなり人間らしい文章が生成できるようになったのです。
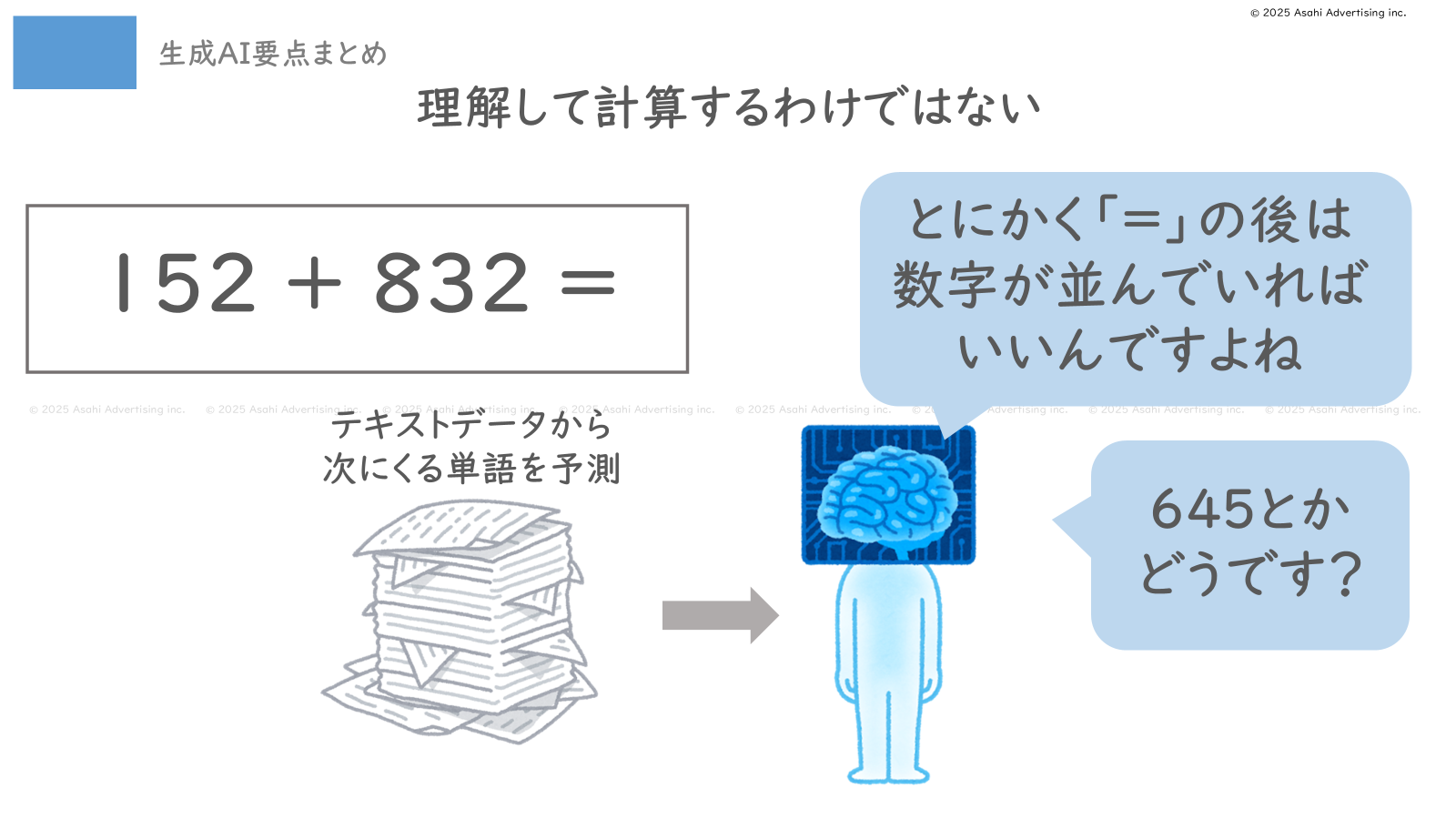
言い換えれば、テキスト生成AIは与えたテキストデータから次に来やすい単語を予測しているだけであり、その内容を人間が持つような「意図」や「意識」を持って理解しているわけではありません。
人間は「りんご」という文字を見ると、実際のりんごを見た経験、味わった経験、香りの記憶など、五感を通じた理解をしますが、生成AIは「りんご」という単語が「食べる」「赤い」「甘い」といった単語と一緒に使われやすいという統計的なパターンを学習しているだけです。
また、「158+832=」というテキストを与えても、数式を見て実際の計算を行うわけではありません。たまたま「158+832=990」という正しい計算例をたくさん学習していたら、正しい答えである990を出すこともありますが、単に「『=』の後には数字が続く」というパターンしか学習していない場合は、適当な数字を並べることもあります。
また、学習用に用意した膨大なテキストデータに含まれていない情報は、当然ながら知らないので答えられません。
例えば2020年までのテキストデータしか与えていなかったら、「2025年の日本の総理大臣は?」と尋ねても、「2025年」「総理大臣」という言葉と「石破茂」がセットでよく出てくると学習できていないので、異なる人名を回答したりします。
以上をまとめると、「LLMは過去のテキストデータを学習して、人間のような自然な文章を作成できる仕組み。ただし、過去のデータから次に来やすい単語を予測しているだけであって、正解を述べているわけではない」ということになります。
このあたりがテキスト生成AIのコアの部分として押さえておきたいポイントです!
生成AIの大まかな動向は?
SNSやらテレビやら本やら、生成AIについて話題になってない日はないくらいの状況で、混乱しちゃいますよね。
私が見た限りでは、今あるニュースは大きく3つのカテゴリに分類できそうな気がします。
- ①生成AIの可能性追求 「こんなことできるようになったよ系ニュース」
- ②生成AI×〇〇で差別化 「掛け合わせたらすごいよ系ニュース」
- ③生成AIが引き起こした摩擦 「なんだよ勘弁してくれ系ニュース」
①生成AIの可能性追求 「こんなことできるようになったよ系ニュース
なにかと話題になりやすいカテゴリです。
このカテゴリの中でもさらに「①-A:生成AI自体の機能向上」系のニュースと「①-B:生成AIの出力コントロール」系のニュースに区分できます。
①-A:生成AI自体の機能向上
「生成AIが大学入試の問題を突破した」といったニュースをよく耳にしますよね。
GPUなどのハードウェアの性能向上(計算力向上)や、学習元となるインターネット上のデータの爆発的な増加に伴って、生成AI自体の性能が日々すさまじい勢いで進化しています。
OpenAIだけでなく、Microsoft、Google、Metaといった世界的大企業も生成AIに参入し、新しい生成AIサービス開発や性能向上に向けて取り組んでいます。
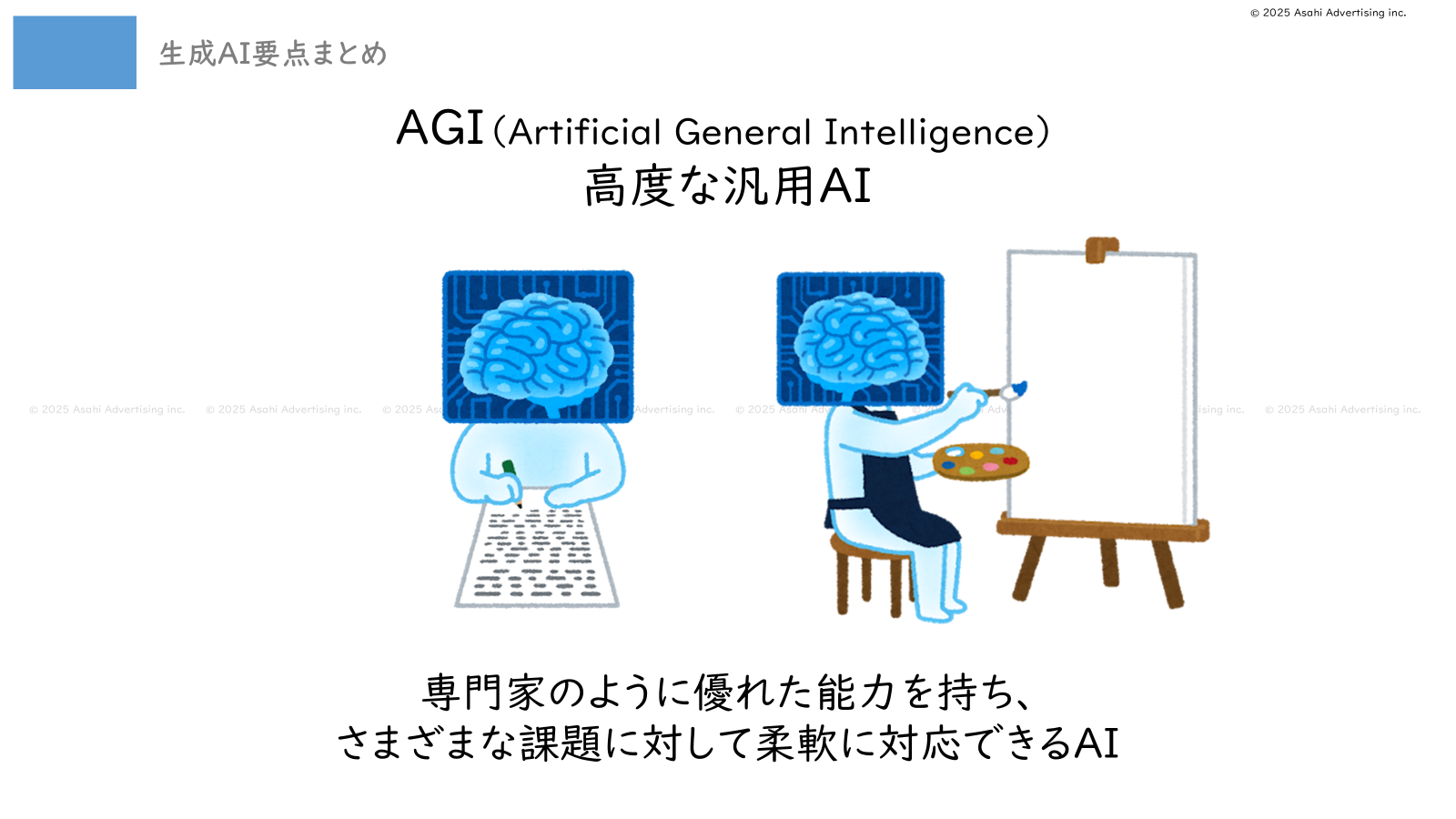
これらの取り組みは大きく、「AGI(Artificial General Intelligence:(高度な)汎用AI)」を目指して開発が進められていると考えられます。
AGIは簡単にいえば、「高度な能力を持った人間のようなAI」です。専門家のように優れた能力を持ち、さまざまな課題に対して柔軟に対応できるAIです。
このAGIを目指して、「推論技術の向上」、「専門分野の知識の学習」、「テキストや画像、音声などの同時処理技術(マルチモーダル)」といった取り組みが現在行われており、話題になっている事項です。
このようなニュースを見たら、「AGIの実現にまた一歩近づいたのだな」と捉えると良いかもしれません。
①-B:生成AIの出力コントロール
「一歩一歩考えよう」と生成AIに入れると精度が上がる!というような話を聞いたことはありますでしょうか。
ChatGPTのようなテキスト生成AIに質問する文章を「プロンプト」というのですが、このプロンプトに入れる文章が変わると、生成AIの回答の質も変化します。(なお、筆者はChatGPTに常に関西弁で答えるよう設定しています)

例えばChatGPT-4oに、「年末調整について教えて」とプロンプトを書くと、下記のような回答が返ってきました。

今度は「5歳にわかるように年末調整を教えて」と書くと、下記の出力が返ってきました。
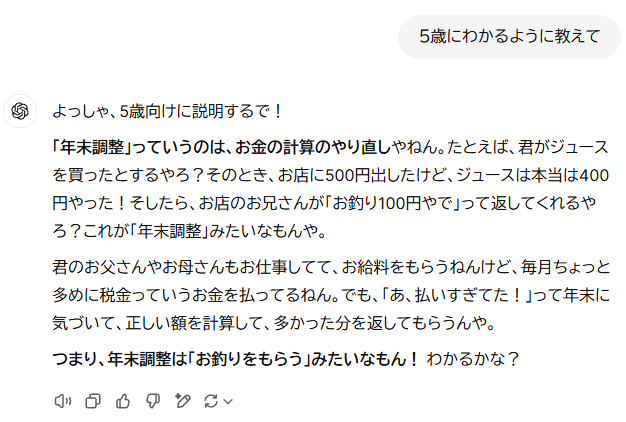
このように出力が大幅に変わりますね。
生成AIは次に出やすい単語を推測して並べていると前半に述べましたが、おそらく「5歳に説明」という言葉を使ったことで、「5歳に説明するときによく使われる語句」が出やすくなったのだと思われます。
こういった、入力する文章(プロンプト)を変えることで、生成AIの出力をコントロールするテクニックを「プロンプトエンジニアリング」と言います。
冒頭の「一歩一歩考えよう」と生成AIに入れると精度が上がるという話も、プロンプトエンジニアリングの話です。このように書くことで、生成AIがいきなり結論を出さずに、考えを少しずつ進めるような段階的な出力をするようになり、結果的に精度が向上するようになることが知られています。このような仕組みは「思考の連鎖(CoT:Chain of Thought)」と呼ばれています。
今、研究者だけでなく一般の人も巻き込んで、どんどん新しいプロンプトの書き方が模索されており、SNSなどで話題になっています。
有名どころではFew-shot(少数例挙げ出し)プロンプトと呼ばれる、回答例を入力時に与えることで希望の回答を出力しやすくするプロンプトや、Role-play(役割設定)プロンプトと呼ばれる、AIに特定の役割や視点を与えることで、回答の質や方向性をコントロールするプロンプトなどがあります。
このあたりの話題は、細かいテクニックはいろいろあるけれども、突き詰めると「人間にとってわかりやすい指示や手順は生成AIにとってもわかりやすい」ということに尽きるなというのが私の所感です。
人間にとっても、ただ「○○せよ」という指示では曖昧すぎますよね。
「前提や背景をきちんと伝える」
「回答に不足する情報や、判断基準があるなら伝える」
「具体的で明確なアウトプットイメージを伝える」
「複雑なものは段階を追って途中段階を評価してあげる」
「試行錯誤を認める」
「意見が分かれそうな問いかけには複数人で相談させたうえで答えさせる」
こういった部分がきちんとされていて、初めて良いアウトプットが出せるのは人間も生成AIも同じです。

したがって、良いプロンプト案が出たというニュースが出たら「人間にとっても役に立つかな?」と思うと面白いかもしれません。
②生成AI×〇〇で差別化 「掛け合わせたらすごいよ系ニュース」
生成AIという強力なAIと既存のものを組み合わせることで、大きな強みを発揮したというタイプのニュースです。
このカテゴリのニュースも大きく下記の2つに分かれるように感じます。
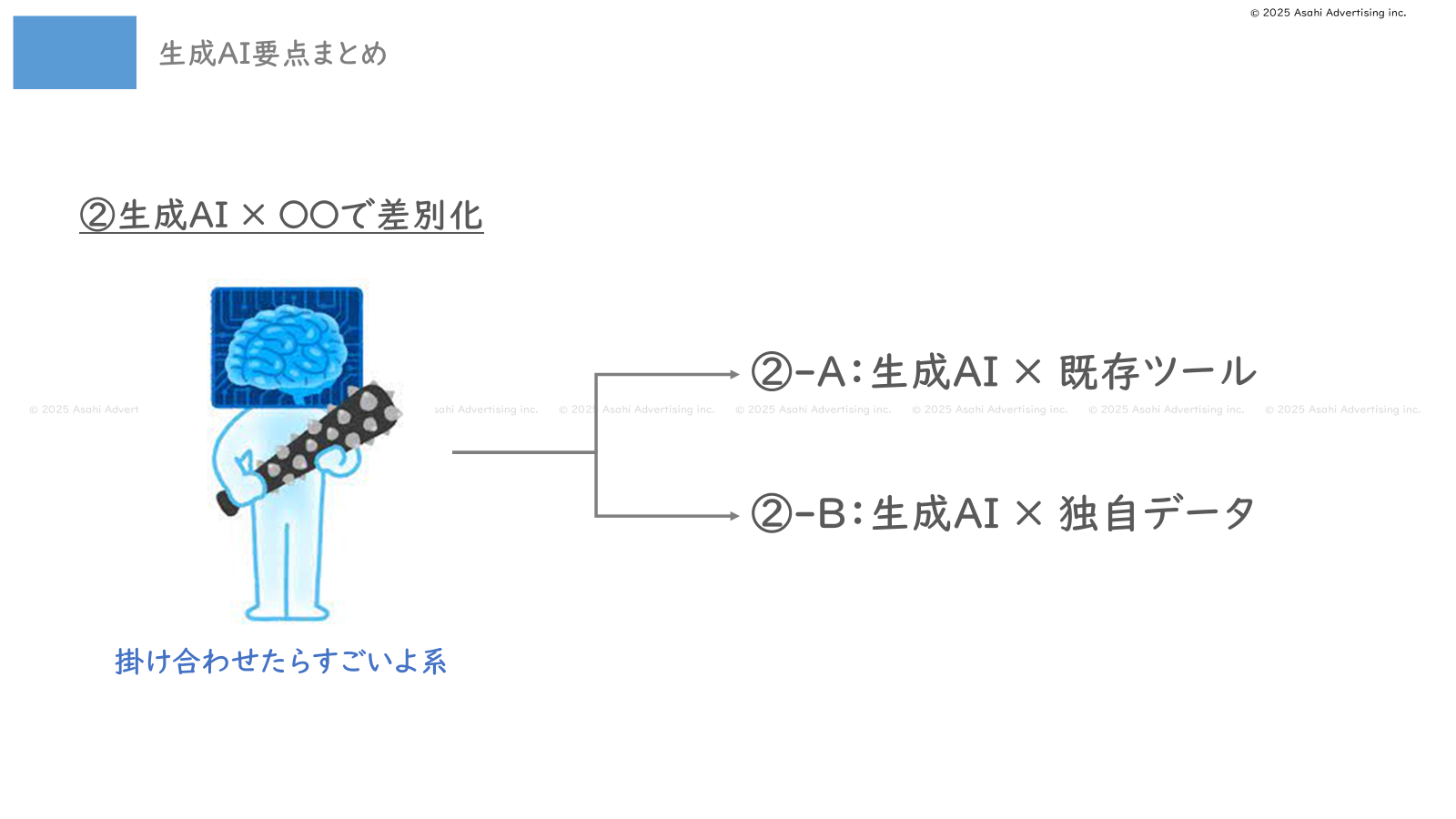
②-A:生成AI×既存ツール
昔からよく使われているツールに、生成AIが融合することで、さらに便利なツールへと生まれ変わった――こんなニュースが日々飛び交っていますね。最近ではスマートフォンのようなデバイスにも生成AIが搭載され、大きな話題となっていました。
既存ツールに生成AIが組み込まれると、どのようなことが起きるのでしょうか?
例えば、表計算ツールに「先月の売上をグラフ化して」と書けば、自動でグラフを作成してくれたり、画像編集ソフトに「背景をぼかして」と伝えればそのように修正してくれたりと、手間の掛かる作業を日本語で指示するだけであっという間にやってくれる時代となりました。
私の感想としては、細かい最終的な仕上げはまだまだ人間の手が必要なレベルではあるのですが、大まかな下準備はさっと生成AIがやってくれるので、とても便利に感じています。
特にプログラムを書く際は、マニュアルやらをひたすら調べることにかなりの時間を費やしていたのですが、今は生成AIがさっと下書きのコードを書いてくれるので、自分は考える作業のほうに時間を掛けられるようになりました。
このように既存ツールに生成AIが組み合わさることで、まるで「そのツールの使い方に習熟した部下に、作業を指示する」といったようなことができるようになったわけです。
当然ながら、指示が曖昧ではアウトプットは微妙なものになりますし、最終的には自分の手を動かす必要はありますが、専門家にとっては「より本質的な作業に時間を使える」というメリット、素人にとっては「詳しくないことでもそれなりのアウトプットがすぐ作れる」というメリットがあります。
今後もさまざまなツールで生成AIの組み込みが進むと思いますが、それ以上に「生成AIにいくつかのツールの使用権を与えて、状況に応じてそれらをうまく使って回答させる」という仕組みが進むと思われます。
例えば生成AIに「最近の広告業界の動向をまとめて」と依頼すると、Webブラウザを立ち上げて情報を収集し、そこから取得したデータを表計算ソフトに入れてグラフを作成、その後はスライド作成ツールを立ち上げてプレゼンテーション資料を作成するといった具合です。
このような、AIが自律的に仕事を進める仕組みを「AIエージェント」と呼んだりもします。まるで、ロボットの部下を自分のPCの前に座らせて、そのPCで好きに作業させるような仕組みですね。

ひとつのツールに生成AIを組み込むだけではそのツールしか便利になりませんが、AIエージェント方式ならばツールの外にある生成AIが、あらゆるツールをコントロールすることになるので、より利便性が高くなります。
これからも「〇〇に生成AIが搭載!」というニュースがよく出てくると予測されますが、「ロボットの部下が自分の代わりにいろいろやってくれるのだろうな」と押さえておけばいいと思います。
②-B:生成AI×独自データ
先ほどは既存ツールと生成AIの掛け算の話でしたが、今度は独自データとの掛け算の話です。
前段でも軽く触れたように、生成AIは基本的にインターネット上のデータから知識を学習しています。これは裏を返すとインターネットで見つからない情報の知識は知りません。
例えば生成AIに「私のカバンの内ポケットには何が入っていますか?」と尋ねても「知らない」と返ってくるはずです。
試しに実際にChatGPTに聞いてみたら、下記の返答でした。
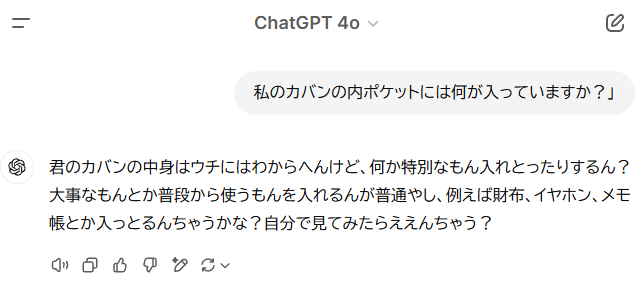
ちなみに「何も入っていない」が正解なのですが、当然わかるはずがありません。
同じように、生成AIに「我が社の交通費の精算方法」や「自社アンケートデータの結果」などを聞いても答えられません。
とはいえ、ポケットの中身はどうでも良いですが、交通費の精算方法やアンケートの結果は答えてくれるようになったら嬉しいですよね。
そのためには、「事前に答えとなる情報を用意しておき、必要なときに生成AIが参照できるようにしておく」という仕組みを用意してあげればOKです。
一番簡単な方法は、プロンプトに入れることです。
試しに前提条件として、「内ポケットには何も入っていない」ということを伝えてみます。
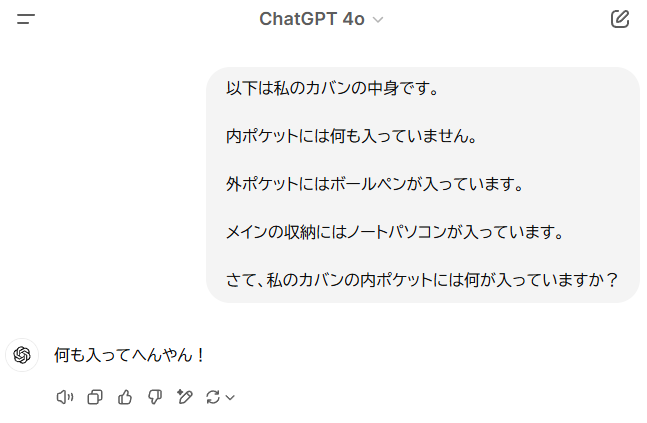
事前に教えたので、きちんと正しい答えが出ましたね。
しかしながらこの方法で「交通費の精算方法」をプロンプトに入れたとしても、交通費の精算方法しか答えてくれません。
現実には交通費の精算方法「しか」教えてくれないAIなんて、役に立たないですよね。
社内のあらゆる手続きに対して精通しており、交通費の精算方法「も」聞けば教えてくれるAIのほうが嬉しいはずです。
そのためには、社内の膨大なマニュアル情報を全部入力しなければいけないですが、面倒です。
そこで、「交通費の精算方法を知りたい」とユーザーが伝えたときに、マニュアルの該当部分から必要な情報を検索してきて、そこだけピックアップして答えさせる方法が考えられました。
これがRAG(Retrieval-Augmented Generation:検索拡張生成)と呼ばれる仕組みです。
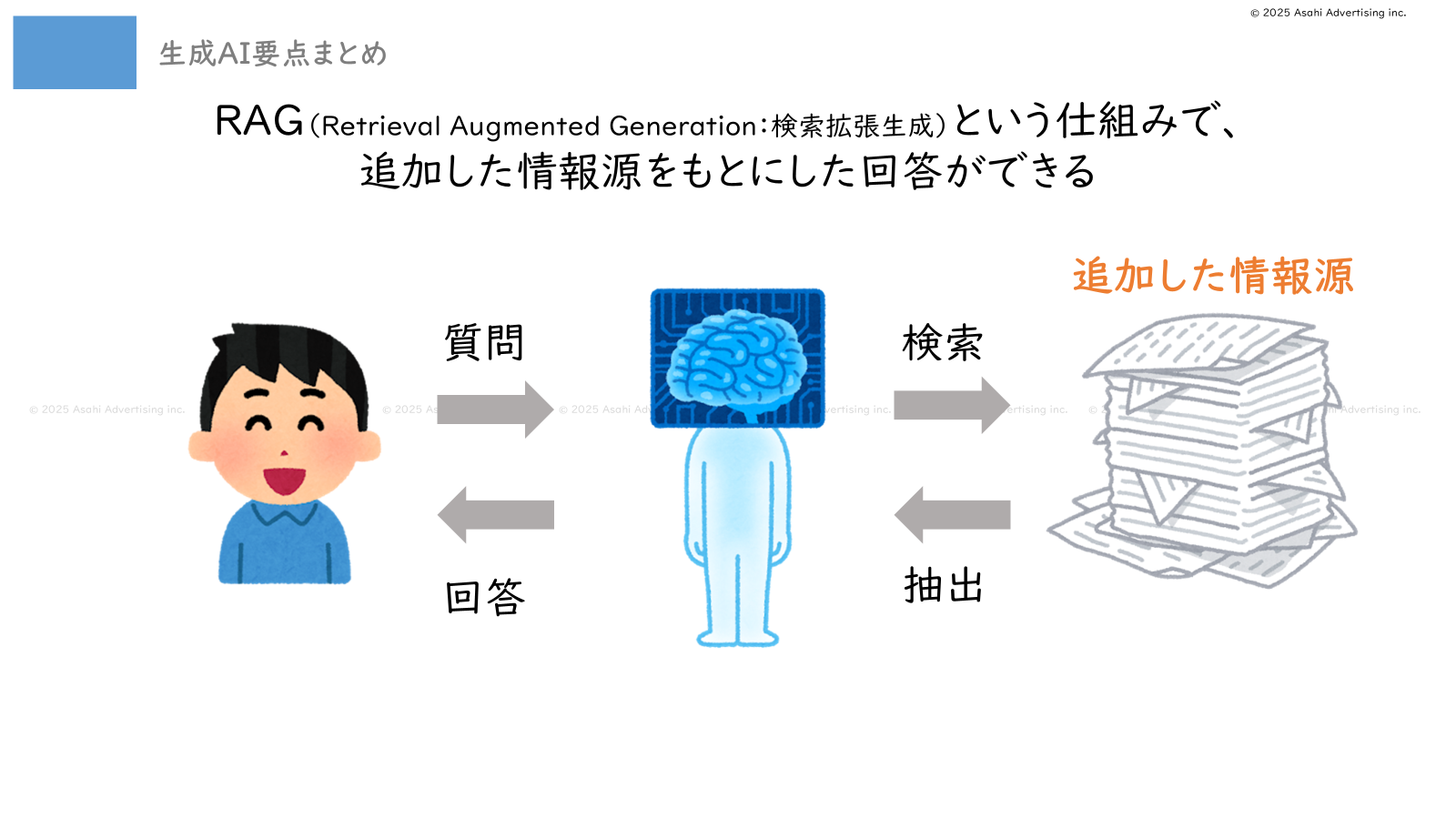
この機能を使った事例で有名なものは、カスタマーサポートのチャットボットです。
ユーザーが「商品の返品方法を教えて」と聞けば、会社の規約やマニュアルを探したうえで、ユーザーがわかりやすいよう、噛み砕いて説明するということができるようになりました。
ほかにも、社内の顧客データを検索できるようにして、新商品のターゲット像や戦略案を作らせるといったことも可能になります。
個人的には、この「生成AI×独自データ」は多くの非テック企業にとって大きなチャンスのある領域だと考えています。
なぜなら「その会社の独自データ」は当然ながら、インターネット上にもなく、グローバルな大企業でも手に入らない情報であるため、オリジナリティのある取り組みができるからです。
以前、私は「会議の音声データを生成AIに入れて文字起こしさせるツール」を勉強がてら趣味で作っていたのですが、今やChatGPTのデフォルト機能として同じことができるようになってしまい、まったく意味のないツールになってしまいました。
誰もが思いつく、オリジナリティのない試みは、このようにすぐに無意味なものになってしまいます。
しかしながら、「独自の調査データとノウハウを使って戦略を作るツール」であれば、同じようなツールを作る会社があったとしても、情報源が異なるので違うアウトプットが生まれることになり、差別化ができますよね。
したがって、「独自データやノウハウ」はこれまで以上に会社の資産として重要な世の中になっていくと考えられます。
まとめると「生成AIに○○のデータを教えた!」というニュースを今後見かけたら、「オリジナリティのある独自のアウトプットができるツールが生まれたのだな」とざっくり理解しておけばいいと思います。
③生成AIが引き起こした摩擦 「なんだよ勘弁してくれ系ニュース」
こちらは言わずもがなの、生成AIにまつわるさまざまな問題のニュースです。
生成AIはまだ登場して間もないのにも関わらず、多くの人が活用しているという点で、まだまだトラブルが絶えない状況です。
個人的には、このあたりはざっくり理解しては危険な領域なので、自分と関係のありそうな領域については詳しく調べておくことを推奨します。
とはいえ、特に押さえておくべきポイントは下記の3つです
1. 誤情報の生成(ハルシネーション)
最初に述べた通り、テキスト生成AIは「人間のような自然な文章」を作るAIであり、「正解を教えてくれる」AIではありません。事前に学習したテキストデータから、次に続きそうな単語を並べるという原理で動いています。
だからこそ、間違っている回答を思わず信じてしまいそうな自然な文章で書いてくる可能性があり、このような誤情報の生成をハルシネーション(幻覚)と呼びます。
個人的には、自分で正解かどうか検証できないことを、生成AIに尋ねるのはそもそも使い方としてあまり正しくないと考えています。どちらかというと生成AIには「飲み会のお礼メールの内容を考えて」といったような、正解はないけれども自分でクオリティを評価できるようなことに使うほうが適切だと感じています。
最終的な判断や検証は自分で行うという心構えが、ハルシネーションに踊らされないための予防策になると考えます。
2. 機密情報の漏洩
生成AIはテキストデータを学習し、その回答の精度を高めることができます。
ここで、プロンプトに「我が社は○○社で、2025年の商品Aの粗利は△△円です」という情報を入力したとします。
このとき、使う生成AIが「プロンプトに入れた入力を学習して他の人の回答に使用する」というモードになっていると、別の人が「○○社の2025年の商品Aの粗利を教えて」と聞いたときに「△△円です」と生成AIが回答するようになります。
つまりは機密情報が漏洩するわけですね。
もちろんメジャーどころのサービスでは、上記のようなことはないようにデフォルトで設定されていたり、オプトアウトなど、避ける仕組みが用意されているはずです。
とはいえプロンプト情報をどう扱うかは使用する生成AIのサービスによっても時期によっても変わる可能性がありますので、こちらはサービスの規約などをしっかりと読んだうえでご利用ください。
特に機密情報を扱う場合は、専用のセキュリティが確保されたサービスをご利用いただくことをお勧めします。
もちろん、そのような環境であっても個人情報の入力は避け、機密情報についても万が一の漏洩リスクを考慮して、入力する情報の範囲や内容には充分ご注意ください。
3. 著作権侵害
生成AIは学習したデータをもとに出力を生成する仕組みですので、どんなデータを学習したのか、生成AIを使った出力を公開する場合はよくよく注意が必要です。
特に画像生成AI周りでは、無断で自分の絵を学習されたと声を上げている人のニュースをよく耳にします。画像を生成した際は、その画像が他者の権利を侵害するものでないか、類似性などを念入りに確認しましょう。
たとえ生成AIの開発元の国では問題がなくとも、日本においては法律違反になることもありますし、逆も然りです。
また、法律的にはOKでも倫理的に問題がある、と多くの人が思うような使い方は慎重になったほうがよいでしょう。
まとめ
以上が忙しい人向けの、生成AI周りのざっくりまとめです。
なにかの参考になれば幸いです。
……忙しいから要約してほしい?
それでは生成AIを使ってこの記事を要約してみましょう。
------------------------------------------------------------------------
そもそも生成AIとは
生成AIは人間のような自然なアウトプットを生成できるAI
従来のAIは決められた課題を正確に判断・処理
生成AIは学習した知識を新しく組み合わせ、柔軟に対応
大規模言語モデル(LLM)とは
人間のように言葉を高度に理解する仕組み
過去のテキストデータから次に来やすい単語を予測
データにない情報は答えられない
理解しているわけではなく、確率的に単語を並べている
①生成AIの可能性追求
機能向上:AGI(高度な汎用AI)実現に向けた開発が進行
出力コントロール:プロンプトエンジニアリングによる精度向上
人間にとってわかりやすい指示が生成AIにもわかりやすい
②生成AI×〇〇で差別化
既存ツール連携:より本質的な作業に時間を使える
独自データ活用:RAG技術で会社独自の情報を活用可能
オリジナリティのある取り組みが重要
③生成AIが引き起こした摩擦
誤情報生成(ハルシネーション)に注意
機密情報の漏洩リスクに留意
著作権侵害の可能性を考慮
------------------------------------------------------------------------
うーん、みごとな要約です。すごい時代ですね。
注意点には気を付けつつ、積極的に生成AIを試してみて、より良い使い方を一緒に模索していきましょう!

- 所属等は執筆当時のもので、現在とは異なる場合があります。
- また記事中の技術、手法等については、今後の技術の進展、外部環境の変化等によっては、実情と合致しない場合があります。
- 各記事における最新の動向につきましては、当社までぜひお問い合わせください。
著者プロフィール

プロフェッショナルズ中野 拓馬(なかの たくま)
この人の書いた記事
- 【データ分析から探るシニア像】〜シニアの幸せとは︖〜
- 【データ分析から探るシニア像】~デジタルシニアってどんな人?~
- 「MMMって何ですか?」~データアナリストに聞いてみた!
- 「データ分析って何ですか?」~データアナリストに聞いてみた!
得意領域
- #MMM
- #AI
- #データアナリシス
- #機械学習
- #CX/DX
- #デジタル
- #効果検証
【転載・引用について】
本記事・調査の著作権は、株式会社朝日広告社が保有します。
転載・引用の際は出典を明記ください 。
「出典:朝日広告社「アスノミカタ」●年●月●日公開記事」
※転載・引用に際し、以下の行為を禁止いたします。
- 内容の一部または全部の改変
- 内容の一部または全部の販売・出版
- 公序良俗に反する利用や違法行為につながる利用